NLP 훑어보기: TF-IDF부터 Transformer까지
자연어 처리(NLP)는 텍스트를 숫자로 표현하고, 그 숫자 사이의 관계를 학습해 의미 있는 결과를 만드는 분야입니다. 이 글에서는 TF-IDF와 BM25 같은 전통적인 검색 기법부터 Word2Vec, RNN, Attention, Transformer까지 큰 흐름을 훑어보겠습니다.
TF-IDF와 BM25
TF-IDF는 주어진 키워드의 빈도수(Term Frequency)를 역문서빈도(Inverse Document Frequency)와 곱한 값입니다.
역문서빈도는 전체 문서 중 해당 키워드를 포함하는 문서 수를 역으로 반영합니다. 흔한 단어일수록 IDF 값이 낮아지고, 특정 문서에 자주 등장하지만 전체 문서에서는 드문 단어일수록 높은 값을 갖습니다. 여기에 로그를 씌우는 이유는 문서 수가 커질수록 IDF 값의 차이가 지나치게 커지는 것을 완화하기 위해서입니다.
정리하면 TF는 한 문서 안에서 해당 키워드가 얼마나 자주 등장하는지를 나타내고, IDF는 그 키워드가 전체 문서에서 얼마나 희소한지를 나타냅니다. 문서는 각 단어의 TF-IDF 값으로 이루어진 벡터로 표현됩니다. 이후 질의가 들어오면 질의의 TF-IDF 벡터와 문서 벡터 사이의 코사인 유사도를 계산해, 유사한 문서를 제시할 수 있습니다.
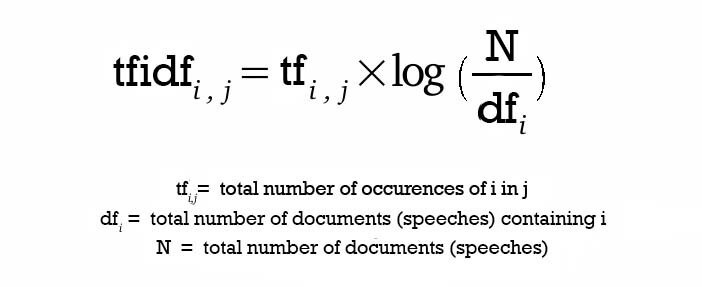
BM25는 TF-IDF 기반 검색 점수를 개선한 랭킹 함수입니다. TF-IDF의 단순한 빈도 기반 점수에 문서 길이 정규화와 smoothing을 더해, 검색 결과의 품질을 높입니다.
공식의 왼쪽 항은 IDF이고, 오른쪽 항은 TF를 정규화한 부분입니다. f_td는 문서 d에서 단어 t가 등장한 빈도입니다. 분모의 k, b는 상수 파라미터이며, 문서 길이 l(d)를 평균 문서 길이 avgdl로 나눈 값도 정규화에 사용됩니다.
IDF 부분에서 N은 전체 문서 수, df_t는 해당 단어를 포함하는 문서 수입니다. 여기에 0.5를 더해 분모가 0이 되는 상황을 피합니다. 일종의 smoothing이라고 볼 수 있습니다.
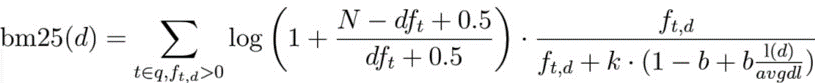
빈도에서 의미로: 차원 축소 기법
Linear Discriminant Analysis: 선형 판별 분석
차원 축소의 간단한 방법으로 1990년대에 사용되었던 선형 판별 분석(Linear Discriminant Analysis)이 있습니다. 이 방법은 이진 분류를 위해 미리 분류명이 붙은 훈련 데이터가 필요합니다.
먼저 한 부류에 속한 TF-IDF 벡터들의 평균 위치, 즉 무게중심을 구합니다. 다른 부류의 TF-IDF 벡터 평균 위치도 구한 뒤, 두 무게중심을 잇는 직선을 만듭니다. 새로운 데이터를 분류할 때는 이 직선 벡터와 데이터의 TF-IDF 벡터를 내적해, 데이터가 어느 쪽 부류에 더 가까운지 판단합니다.
LSA: 잠재 의미 분석
잠재 의미 분석(LSA, Latent Semantic Analysis)은 TF-IDF 벡터를 분석해 문서의 주제를 추출하는 알고리즘입니다. 선형 판별 분석이 이진 분류를 위한 지도 학습 방법에 가깝다면, LSA는 주제를 미리 정하지 않아도 되는 비지도 학습 방법입니다.
LSA는 이미지 같은 고차원 자료의 차원을 줄이는 데 쓰이는 PCA(Principal Component Analysis)에서 아이디어를 가져왔습니다.
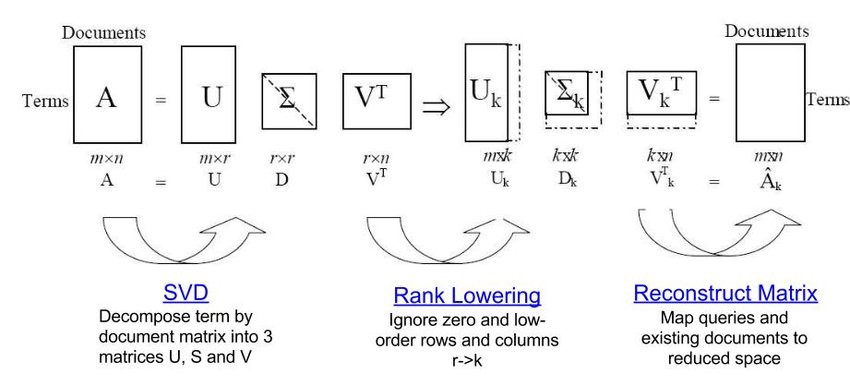
LSA는 특잇값 분해(SVD, Singular Value Decomposition)를 사용해 용어-문서 행렬 또는 TF-IDF 행렬로부터 주제-문서 행렬을 생성합니다.
SVD는 원래의 행렬을 세 개의 행렬 곱으로 분해합니다. 이때 U, V는 직교 행렬이고, S 또는 Sigma는 대각 행렬입니다. 대각 행렬 S의 대각 원소를 행렬의 특잇값(singular value)이라고 합니다. S의 크기는 주제 수와 연결되며, 이 크기를 줄이면 Truncated SVD가 됩니다.
LDA: 잠재 디리클레 할당
LDA(Latent Dirichlet Allocation)는 문서가 여러 주제를 조금씩 포함하고 있으며, 각 단어는 그중 하나의 주제에서 선택되었다고 가정합니다.
예를 들어 [자전거, 한강, 수영복, 바다] 같은 단어가 있다고 해보겠습니다. 문서 1은 [자전거, 한강], 문서 2는 [수영복, 바다], 문서 3은 [한강, 바다]로 구성될 수 있습니다. 이때 주제가 [바이킹, 수영, 여행]이라면, 문서 1은 바이킹 0.7, 수영 0.1, 여행 0.2처럼 여러 주제를 비율로 가질 수 있습니다.
이를 반대로 생각하면, 문서 1이 [자전거, 한강]을 포함할 때 어떤 주제에 가까운지도 추정할 수 있습니다.
먼저 문서 집합에 존재하는 주제 k개를 설정합니다. k개의 주제는 디리클레 분포에 따라 각 문서에 분포되어 있다고 가정합니다. 그리고 문서별 단어를 k개 주제 중 하나에 할당합니다. 어떤 단어가 올바른 주제로 분류되기 위해서는, 그 단어가 다른 문서에서는 어떤 주제로 분류되었는지와 해당 문서의 다른 단어들이 어떤 주제로 분류되었는지를 함께 확인합니다. 이 과정을 전체 문서의 단어에 대해 반복하면 일정한 값으로 수렴합니다.
Word2Vec
LSA가 한 문서의 의미 또는 주제를 파악하는 데 가깝다면, Word2Vec은 개별 단어의 밀집 벡터 표현을 추출합니다. 한 단어의 의미는 주변 단어를 보면 알 수 있다는 가정에서 출발합니다.
Word2Vec은 크게 Skip-gram과 CBOW(Continuous Bag of Words) 두 가지 방법으로 단어 벡터를 구합니다.
예를 들어 오늘 점심은 맛있는 햄버거라는 문장이 있다고 해보겠습니다. Skip-gram은 맛있는을 입력으로 넣었을 때 오늘, 점심은, 햄버거 같은 주변 단어를 예측합니다. 반대로 CBOW는 오늘, 점심은, 햄버거를 입력했을 때 맛있는을 예측합니다.
단어 벡터를 추출할 때 중요한 것은 최종 출력 자체가 아니라, 학습 과정에서 만들어진 은닉층의 가중치입니다. 입력이 원-핫 벡터이기 때문에 해당 입력 단어에 영향을 미친 가중치를 단어 벡터로 사용할 수 있습니다.
CNN
주로 2차원 이미지 도메인에 사용하는 CNN(Convolutional Neural Network)도 텍스트에 적용할 수 있습니다. 텍스트에서는 1차원 합성곱 필터를 통해 단어 사이의 지역적인 관계를 파악합니다.
단어-벡터 행렬 위에서 수평으로 이동하는 합성곱 필터를 사용해 입력 전체에 합성곱 연산을 수행합니다. 이 연산은 필터 안에 있는 단어 임베딩과 필터의 가중치를 곱하고 더한 뒤, 주로 ReLU 같은 활성화 함수를 적용하는 방식입니다. 각 스텝은 독립적으로 계산할 수 있기 때문에 병렬 처리가 가능합니다.
각 합성곱 필터는 서로 다른 출력을 만들고, 이 출력은 다음 단계 신경망의 입력으로 전달됩니다. 이후 pooling으로 차원을 줄이거나, dropout을 통해 과대적합을 줄일 수 있습니다. 마지막 층에서는 각 데이터에 대해 하나의 값으로 표현하기 위해 활성화 함수를 적용합니다. 이 값은 손실 함수로 전달되어 오차를 계산하고, 역전파를 통해 필터의 가중치를 갱신합니다. 손실을 줄이기 위해 Adam, RMSProp 같은 optimizer를 사용합니다.
RNN과 LSTM
CNN이나 Word2Vec은 주로 주변 단어를 통해 패턴을 파악합니다. 하지만 텍스트에는 멀리 떨어져 있어도 의미적으로 연결되는 단어가 많습니다. 이런 순차 정보를 다루기 위해 RNN(Recurrent Neural Network)이 사용됩니다. RNN은 현재 시점 t의 출력을 다음 시점 t+1의 입력으로 전달합니다.
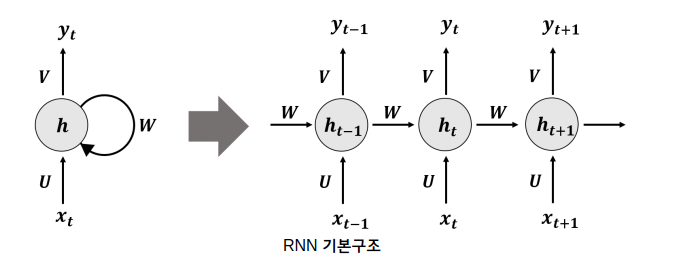
RNN의 역전파는 BPTT(BackPropagation Through Time)라고 합니다. 마지막 단계의 출력에서 목표값과의 오차를 구한 뒤, 이전 단계의 가중치가 얼마나 기여했는지를 거슬러 올라가며 계산합니다. 문제는 신경망의 층이 깊어질수록 기울기 소실 또는 기울기 폭발 문제가 발생하기 쉽다는 점입니다.
LSTM(Long Short-Term Memory)은 이런 기울기 문제를 완화하면서 RNN의 기억 능력을 강화한 구조입니다. 신경망의 각 단계에 상태(state)를 도입해, 다음 단계로 갈수록 입력 텍스트 전체를 아우르는 기억을 생성합니다.
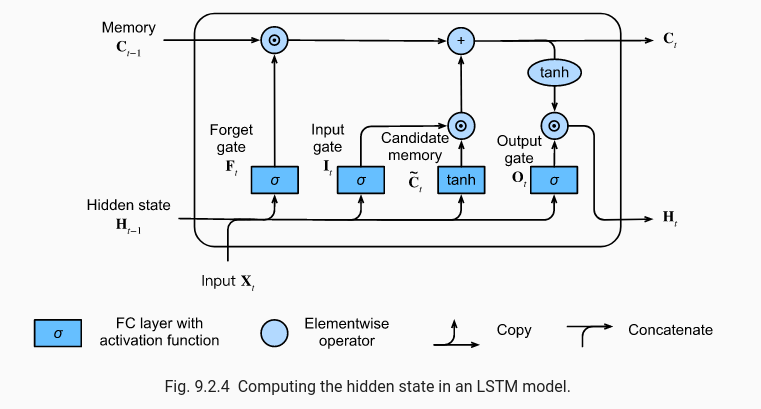
이 기억 상태는 세 개의 게이트를 통과합니다. 망각 게이트는 필요 없는 기억을 제거하고, 후보 게이트는 새롭게 강화할 성분을 선택합니다. 마지막으로 출력 게이트는 갱신된 기억 벡터와 입력 데이터를 바탕으로 활성화 함수를 적용해 출력을 만듭니다. 이 출력은 다음 단계의 LSTM으로 전달됩니다.
비슷한 구조로 GRU(Gated Recurrent Unit)도 많이 사용됩니다.
Seq2Seq와 Attention
Seq2Seq는 LSTM 또는 GRU로 이루어진 인코더와 디코더 구조를 뜻합니다. 입력 텍스트를 인코더에 넣어 벡터를 만들고, 이 벡터와 기대 출력값을 디코더에 넣어 결과를 생성합니다. 입력과 출력의 길이가 다른 번역 태스크에 적합하며, LSTM의 특성상 가변 길이 텍스트를 생성할 수 있습니다.
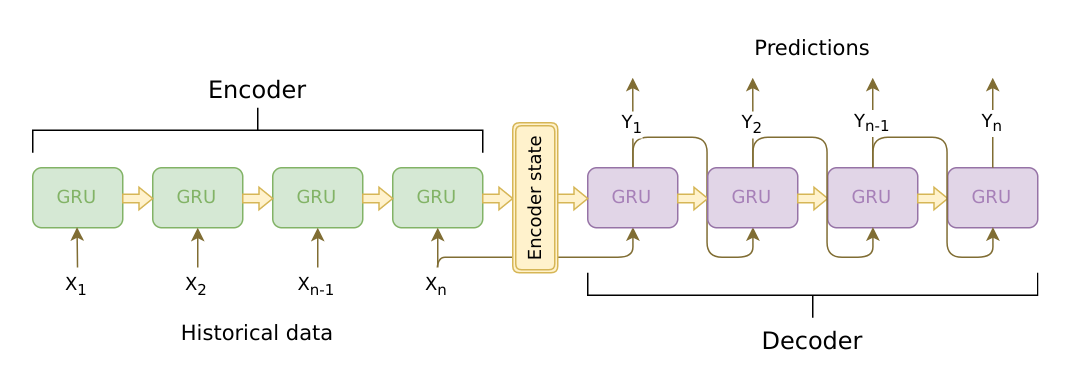
하지만 Seq2Seq 모델은 입력 텍스트를 고정된 크기의 벡터로 표현합니다. 텍스트가 길어질수록 하나의 벡터 안에 모든 의미를 잘 압축하기 어려워집니다.
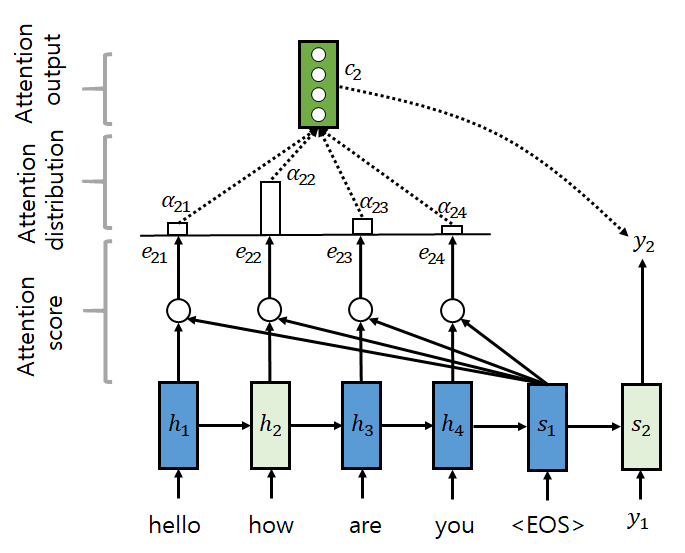
Attention은 디코더가 출력 단어를 예측하는 시점에, 관련 있는 입력 단어를 다시 살펴보도록 합니다. 즉 y_i를 선택할 때 인코더 출력 h_j를 attention weight a_ij만큼 사용합니다. y_i의 context vector c_i는 sum(a_ij * h_j)로 표현할 수 있습니다.
Attention score는 현재 디코더 출력과 인코더 은닉 상태를 통해 계산하고, softmax 함수를 통과시켜 확률 벡터로 만듭니다. 이 벡터와 현재 디코더 출력은 다음 디코더 hidden state를 계산하는 데 사용됩니다.
Transformer
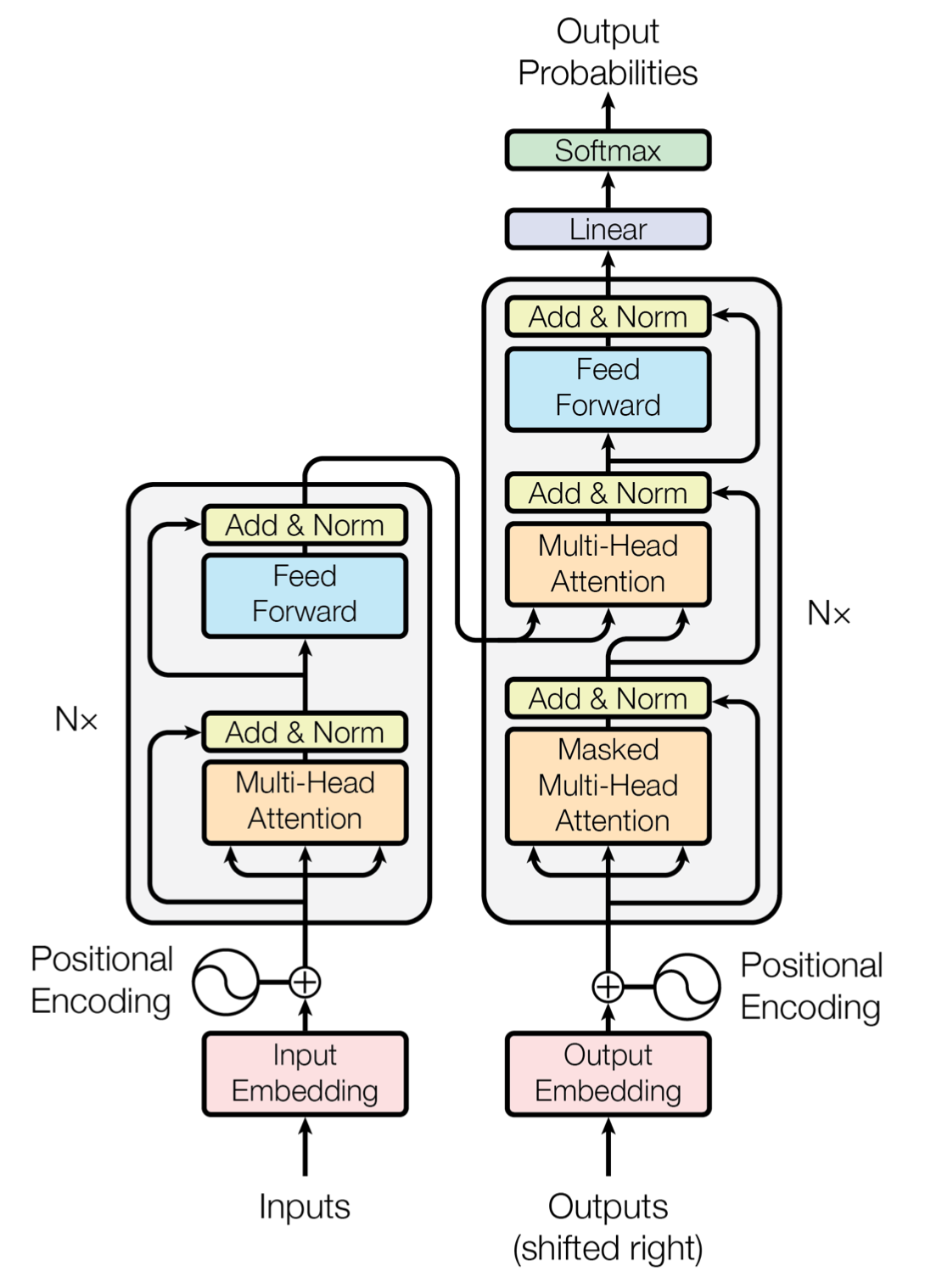
Transformer는 Seq2Seq의 인코더와 디코더에서 사용하던 RNN 기반 신경망을 제거하고, attention만으로 인코더와 디코더를 구현한 구조입니다.
다만 RNN을 제거하면 단어의 순차적인 위치 정보가 사라집니다. Transformer는 이를 Positional Encoding으로 해결합니다. Positional Encoding은 단어 임베딩 벡터의 짝수 위치에는 사인 함수를, 홀수 위치에는 코사인 함수를 적용해 위치 정보를 더합니다.
이렇게 만들어진 단어 임베딩은 인코더에서 Multi-Head Self-Attention을 거칩니다. Attention은 특정 단어의 query와 다른 단어의 key, value 사이의 관계를 계산합니다. 먼저 query와 전체 key 행렬을 내적해 attention score를 구하고, softmax를 통해 확률 값으로 만듭니다. 이후 이 확률 벡터를 value와 곱하면 query와 key의 관계가 value에 가중된 결과를 얻을 수 있습니다.
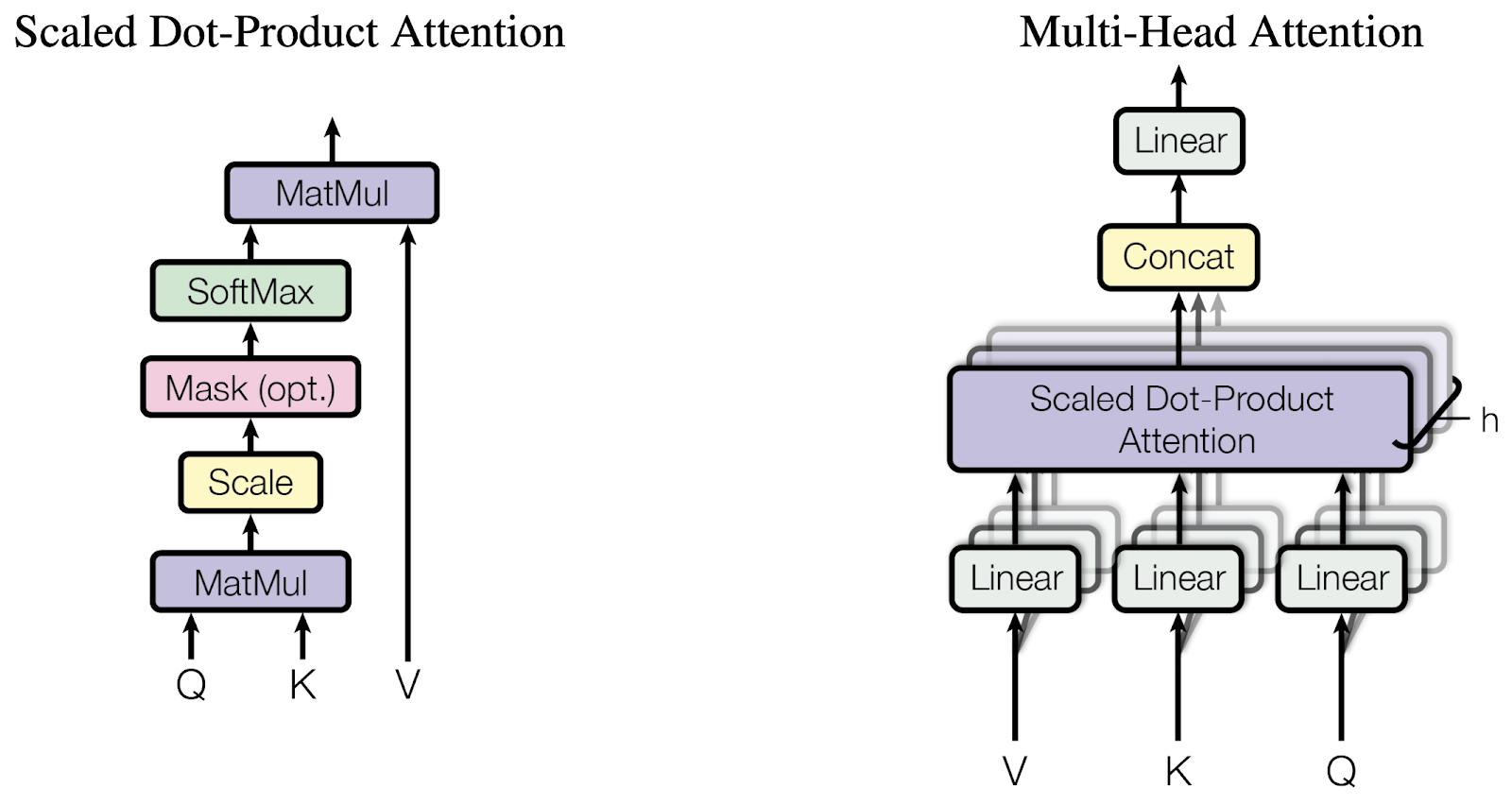
인코더에서는 Q, K, V가 모두 같은 입력에서 만들어지는 self-attention을 수행합니다.
Attention 이후에는 Feed Forward Network(FFN)를 거칩니다. FFN은 첫 번째 선형 레이어에 ReLU를 적용한 뒤, 다시 두 번째 선형 레이어로 계산하는 구조입니다. 이때 선형 레이어의 가중치는 한 인코더 층 안에서는 공유되지만, 다른 층에서는 다른 값을 가집니다.
Attention과 FFN 사이에 있는 Add & Norm은 residual connection과 layer normalization을 의미합니다. Residual connection은 해당 함수의 입력과 출력을 더하는 방식입니다.
이렇게 만들어진 인코더 결과는 디코더로 전달됩니다. 디코더에서도 먼저 self-attention을 수행합니다. 이때 mask는 현재 시점보다 이후의 목표 단어를 참고하지 못하도록, 미래 위치에 매우 작은 값을 부여하는 기법입니다.
디코더의 두 번째 attention은 인코더의 출력값을 key와 value로 사용하고, 디코더의 값을 query로 사용해 인코더 정보를 참고합니다. 이후 동일한 과정을 거쳐 최종 출력 결과를 만듭니다.
정리
TF-IDF와 BM25는 단어의 빈도와 문서 내 중요도를 바탕으로 텍스트를 비교합니다. LSA와 LDA는 문서에 숨어 있는 주제를 찾으려는 시도이고, Word2Vec은 단어 자체를 의미 있는 벡터로 표현합니다. CNN과 RNN, LSTM은 텍스트 안의 패턴과 순서를 학습하려는 신경망 기반 접근입니다.
마지막으로 Attention과 Transformer는 긴 문맥 안에서 어떤 단어를 더 중요하게 볼지 학습하며, 순차 계산의 부담을 줄이는 방향으로 발전했습니다. NLP의 흐름은 결국 “텍스트를 어떻게 숫자로 바꾸고, 그 숫자 사이의 의미 있는 관계를 어떻게 학습할 것인가”라는 질문으로 이어진다고 볼 수 있습니다.