스파크를 다루는 기술 3: 런타임, 스케줄링, 실시간 처리 예제
『스파크를 다루는 기술』 정리 세 번째 글입니다. 이번 글에서는 Spark 애플리케이션을 구성하는 런타임 컴포넌트와 스케줄링 방식을 정리하고, 마지막으로 실시간 대시보드 예제를 살펴봅니다.
앞선 글에서 RDD, 파티셔닝, 셔플링을 다뤘다면, 이번 글은 실제 클러스터 위에서 Spark가 어떻게 실행되는지에 더 가깝습니다.
Spark 런타임 컴포넌트
Spark 애플리케이션은 여러 런타임 컴포넌트가 함께 동작하면서 실행됩니다.
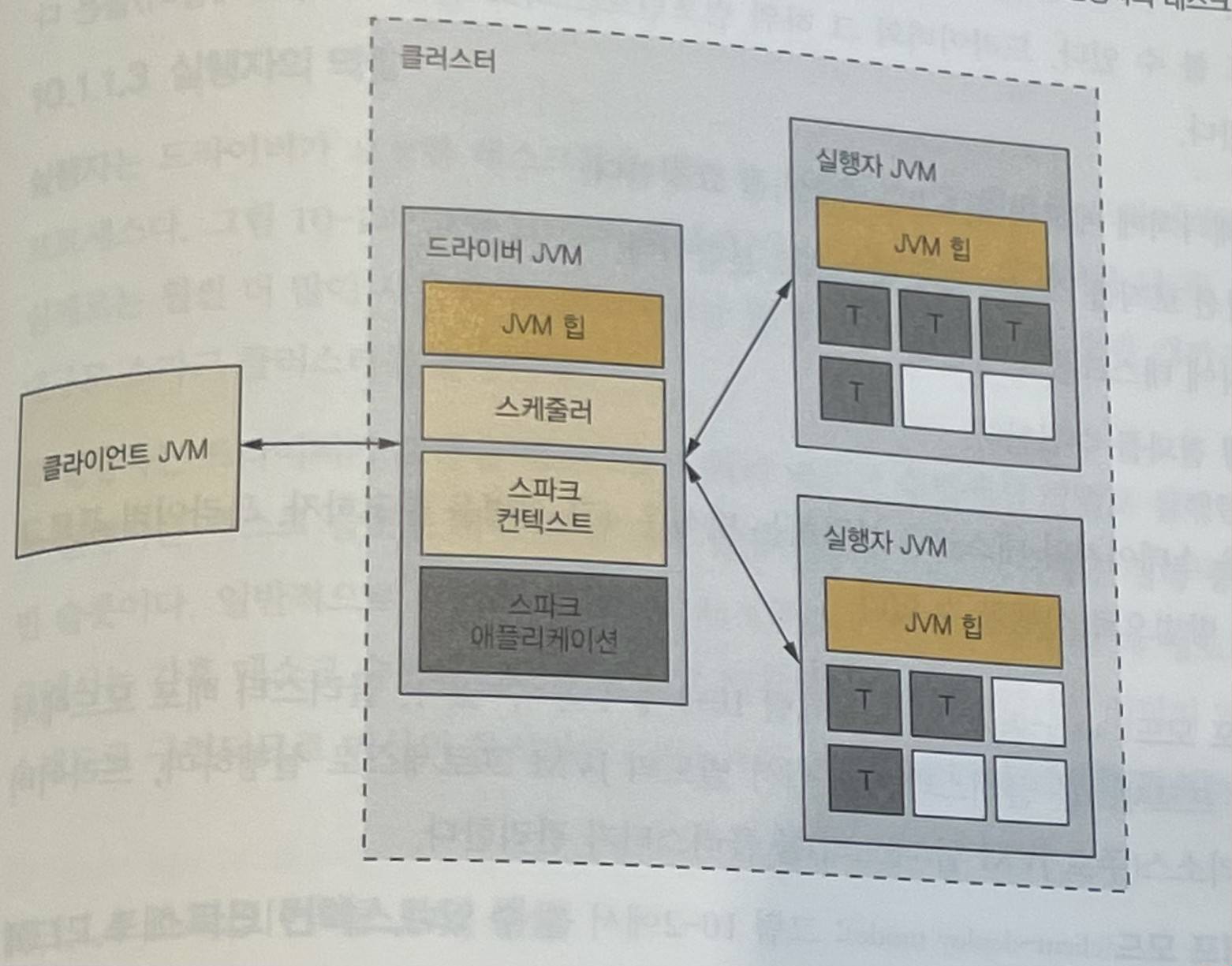
Client
Client는 드라이버를 시작하는 주체입니다. spark-submit, spark-shell, Spark API를 사용한 커스텀 애플리케이션 등이 여기에 해당합니다.
Driver
Driver는 Spark 애플리케이션에 하나만 존재하는 일종의 래퍼 역할을 합니다.
Driver가 담당하는 일은 다음과 같습니다.
- 클러스터 매니저에 메모리와 CPU 리소스를 요청합니다.
- 애플리케이션 로직을 스테이지와 태스크로 분할합니다.
- 여러 executor에 태스크를 전달합니다.
- 태스크 실행 결과를 수집합니다.
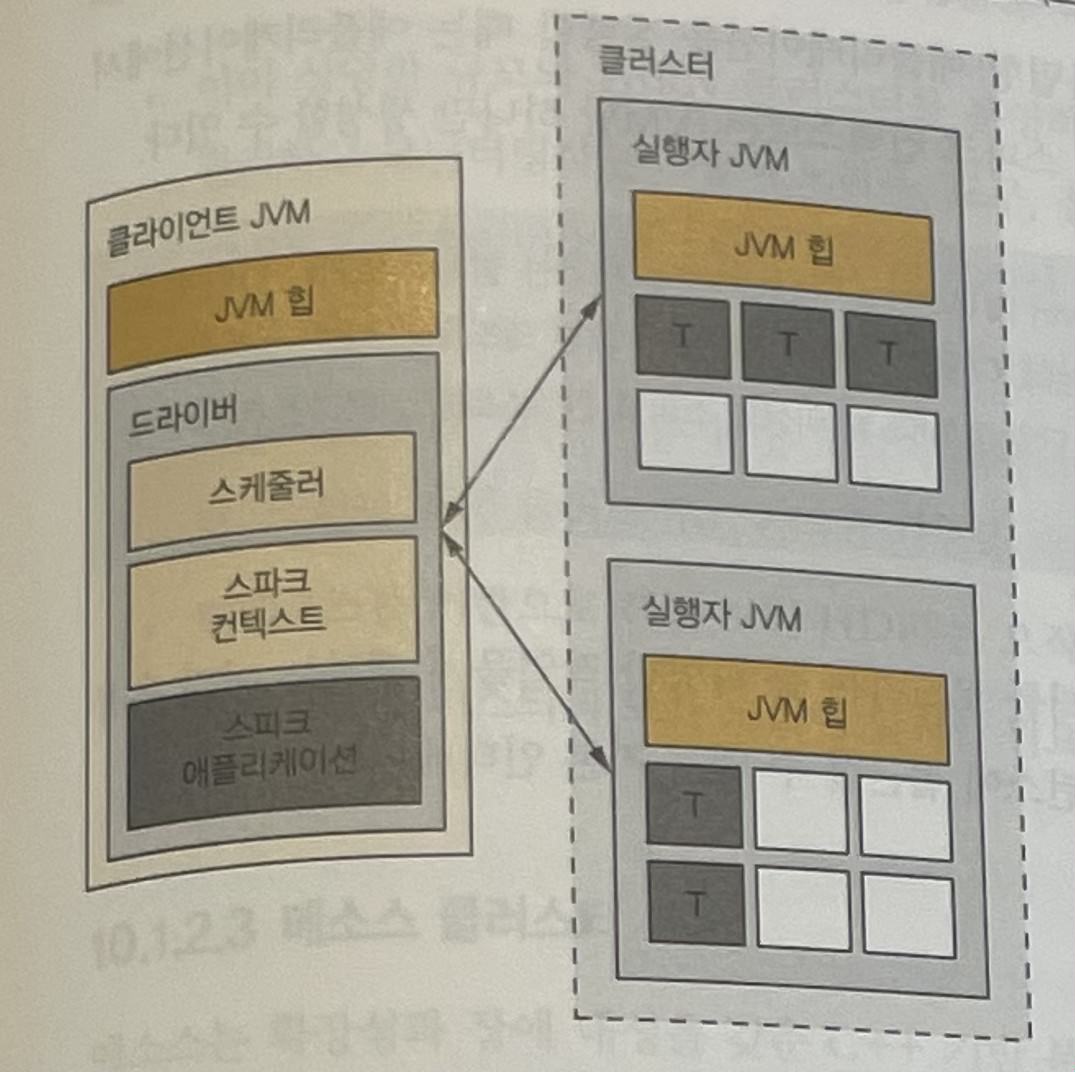
Driver가 어디에서 실행되느냐에 따라 배포 모드는 두 가지로 나눌 수 있습니다.
클러스터 배포 모드
클러스터 배포 모드에서는 driver가 client와 분리됩니다.
Driver는 클러스터 내부에서 별도의 JVM 프로세스로 실행됩니다. 따라서 driver 프로세스의 리소스, 예를 들어 JVM 힙 메모리는 클러스터가 관리합니다.
클라이언트 배포 모드
클라이언트 배포 모드에서는 driver를 client의 JVM 프로세스에서 실행합니다.
Executor
Executor는 driver가 요청한 태스크를 실행하고, 결과를 다시 driver로 반환하는 JVM 프로세스입니다.
Executor는 여러 태스크 슬롯에서 태스크를 병렬로 실행합니다. 일반적으로 태스크 슬롯은 스레드로 구현되므로, CPU 코어의 2~3배 정도로 설정한다고 합니다.
SparkContext
SparkContext는 Spark 런타임 인스턴스에 접근할 수 있는 기본 인터페이스입니다. Driver는 SparkContext 인스턴스를 생성하고 시작합니다.
Spark API로 애플리케이션을 실행할 때는 애플리케이션에서 직접 SparkContext를 실행해야 합니다.
SparkContext는 JVM당 하나만 생성할 수 있습니다. 여러 개를 쓰는 옵션도 있지만 테스트용에 가깝고, 일반적으로는 권장되지 않습니다.
스케줄링
Spark의 스케줄링은 크게 세 관점으로 볼 수 있습니다.
- Executor, JVM 프로세스, CPU 태스크 슬롯 리소스를 스케줄링합니다.
- 클러스터 매니저가 CPU와 메모리 리소스를 각 executor에 할당합니다.
- 애플리케이션 내부에서 잡 스케줄링을 실행합니다.
클러스터 리소스 스케줄링
클러스터 리소스 스케줄링은 단일 클러스터에서 실행되는 여러 Spark 애플리케이션의 executor에 리소스를 할당하는 과정입니다.
클러스터 매니저는 프로세스를 시작, 중지, 재시작하고 executor가 사용할 수 있는 최대 CPU 코어 개수를 제한합니다.
클러스터 매니저가 하는 일은 다음과 같습니다.
- Driver가 요청한 executor 프로세스를 시작합니다.
- 클러스터 배포 모드라면 driver 프로세스도 시작합니다.
애플리케이션 간 executor는 공유되지 않습니다. 따라서 여러 애플리케이션을 한 클러스터에서 동시에 실행하면 리소스 경쟁이 발생할 수 있습니다.
Spark 잡 스케줄링
Spark 잡 스케줄링은 단일 Spark 애플리케이션 안에서 태스크를 실행할 CPU와 메모리 리소스를 스케줄링하는 과정입니다.
Driver에는 여러 스케줄러 객체가 있습니다. Executor가 실행되면 어떤 executor가 어떤 태스크를 수행할지 결정합니다.
동일한 SparkContext를 공유하는 여러 잡은 executor의 리소스를 놓고 경쟁합니다. SparkContext는 thread-safe합니다.
잡 스케줄링은 클러스터의 CPU 리소스 사용량을 좌우합니다. 또한 더 많은 태스크를 단일 JVM에서 실행할수록 더 많은 힙 메모리를 사용하므로, 메모리 사용량에도 간접적인 영향을 줍니다.
CPU 리소스는 태스크 단위로 관리됩니다. 반면 메모리 리소스는 여러 세그먼트로 나누어 관리됩니다.
FIFO 스케줄러
FIFO 스케줄러는 가장 먼저 리소스를 요청한 잡이 필요한 만큼 태스크 슬롯을 차지하는 방식입니다.
먼저 실행된 잡이 리소스를 많이 차지하지 않는다면 다른 잡도 동시에 실행될 수 있습니다. 하지만 먼저 실행된 잡이 모든 리소스를 차지해야 한다면, 다음 잡은 기존 잡이 리소스를 다 사용할 때까지 기다려야 합니다.
FAIR 스케줄러
FAIR 스케줄러는 round-robin 방식으로 리소스를 균등하게 분배합니다.
태스크 슬롯을 더 늦게 요청한 잡이라도, 오래 걸리는 잡이 완료될 때까지 무조건 기다리지 않아도 됩니다.
스케줄러 풀 기능을 사용하면 가중치와 최소 지분을 설정할 수 있습니다. 가중치를 설정하면 특정 풀의 잡이 다른 풀보다 리소스를 더 많이 할당받을 수 있습니다. 최소 지분은 각 풀이 항상 사용할 수 있는 최소 CPU 코어 개수입니다.
태스크 예비 실행
태스크 예비 실행(speculative execution)은 동일 스테이지의 다른 태스크보다 유난히 오래 걸리는 낙오 태스크(straggler task) 문제를 줄이기 위한 기능입니다.
Spark는 해당 파티션 데이터를 처리하는 동일한 태스크를 다른 executor에도 요청할 수 있습니다. 기존 태스크가 지연되고 예비 태스크가 먼저 완료되면, 예비 태스크의 결과를 사용해 전체 작업 지연을 줄입니다.
관련 설정은 다음과 같습니다.
spark.speculation = true: 예비 실행을 활성화합니다.spark.speculation.interval: 예비 태스크 실행 여부를 확인하는 주기입니다.spark.speculation.quantile: 예비 태스크 실행 전 완료되어야 하는 태스크 진척률입니다.spark.speculation.multiplier: 기존 태스크가 얼마나 지연되었는지 판단하는 기준입니다.
다만 예비 태스크는 주의해서 사용해야 합니다. 예를 들어 DB에 데이터를 기록하는 작업이라면 동일 데이터를 중복 기록할 수 있습니다.
데이터 지역성
데이터 지역성(data locality)은 데이터와 최대한 가까운 위치의 executor에서 태스크를 실행하려는 전략입니다.
선호 위치
Spark는 각 파티션별로 파티션 데이터를 저장한 호스트명 또는 executor 목록을 갖고 있습니다. 이 위치 정보를 참고해 데이터와 가까운 곳에서 연산을 실행할 수 있습니다.
다만 HDFS 데이터로 생성한 RDD와 캐시된 RDD만 선호 위치 정보를 알 수 있습니다.
HDFS RDD는 Hadoop API를 통해 HDFS 클러스터의 위치 정보를 가져옵니다. 캐시된 RDD는 각 파티션이 캐시된 executor 위치를 Spark가 직접 관리합니다.
데이터 지역성 레벨
Spark는 가장 좋은 태스크 슬롯을 확보하지 못했을 때 일정 시간 기다립니다. 그래도 확보하지 못하면 차선의 위치로 스케줄링을 시도합니다.
태스크의 실행 위치에 따라 데이터 지역성 레벨은 다음과 같이 나뉩니다.
PROCESS_LOCAL: 파티션을 캐시한 executor에서 실행합니다.NODE_LOCAL: 파티션에 직접 접근할 수 있는 노드에서 실행합니다. 네트워크를 통하지 않고 접근할 수 있는 위치이며, 동일 머신의 다른 executor가 여기에 해당할 수 있습니다.RACK_LOCAL: 파티션을 저장한 머신과 같은 랙에 장착된 다른 머신에서 실행합니다. YARN만 클러스터의 rack 정보를 참고할 수 있어서, 이 레벨은 YARN에서만 가능합니다.NO_PREF: 선호하는 위치가 없는 경우입니다. 클러스터 어디서나 동일한 속도로 데이터에 접근할 수 있습니다.ANY: 데이터 지역성을 확보하지 못했을 때 다른 위치에서 태스크를 실행합니다.
여기서 랙은 서버와 네트워크 장비를 장착하는 표준 크기의 프레임입니다. 같은 랙 안에서는 네트워크로 데이터를 전송하더라도 switch만 거치면 됩니다.
메모리 스케줄링
메모리 스케줄링은 클러스터 매니저가 executor JVM 프로세스에 메모리를 할당하고, Spark가 잡과 태스크가 사용할 메모리를 관리하는 과정입니다.
클러스터 매니저가 관리하는 메모리
Executor에 할당할 메모리는 spark.executor.memory로 설정합니다.
Spark가 관리하는 메모리
Spark 1.5.2 이하에서는 executor 메모리를 나누어 캐시 데이터와 임시 셔플링 데이터를 저장했습니다. 나뉜 메모리의 사용량이 초과될 수 있으므로 safety 비율을 정했고, 기본값은 캐시 54%, 셔플링 16%, 나머지 30%를 기타 Java 객체와 리소스 저장에 사용하는 방식이었습니다.
Spark 1.6.0부터는 메모리를 통합해 관리합니다. 따라서 셔플링이 없다면 캐시가 전체 메모리를 차지할 수도 있습니다. 다만 실행 메모리가 차지한 영역은 스토리지 메모리 영역으로 변경할 수 없습니다.
예제: 실시간 대시보드
마지막으로 실시간 대시보드 예제를 정리합니다.
class KafkaProducerWrapper(object):
producer = None
@staticmethod
def getProducer(brokerList):
if KafkaProducerWrapper.producer == None:
KafkaProducerWrapper.producer = KafkaProducer(
bootstrap_servers=brokerList,
key_serializer=str.encode,
value_serializer=str.encode
)
return KafkaProducerWrapper.producer
if __name__ == "__main__":
# ... 생략
# data key types for the output map
SESSION_COUNT = "SESS"
REQ_PER_SEC = "REQ"
ERR_PER_SEC = "ERR"
ADS_PER_SEC = "AD"
requests = reqsPerSecond.map(lambda sc: (sc[0], {REQ_PER_SEC: sc[1]}))
errors = errorsPerSecond.map(lambda sc: (sc[0], {ERR_PER_SEC: sc[1]}))
finalSessionCount = sessionCount.map(
lambda c: (
long((datetime.now() - zerotime).total_seconds() * 1000),
{SESSION_COUNT: c}
)
)
ads = adsPerSecondAndType.map(
lambda stc: (stc[0][0], {ADS_PER_SEC + "#" + stc[0][1]: stc[1]})
)
# all the streams are unioned and combined
finalStats = finalSessionCount \
.union(requests) \
.union(errors) \
.union(ads) \
.reduceByKey(lambda m1, m2: dict(m1.items() + m2.items()))
def sendMetrics(itr):
global brokerList
prod = KafkaProducerWrapper.getProducer([brokerList])
for m in itr:
mstr = ",".join([str(x) + "->" + str(m[1][x]) for x in m[1]])
prod.send(
statsTopic,
key=str(m[0]),
value=str(m[0]) + ":(" + mstr + ")"
)
prod.flush()
# Each partition uses its own Kafka producer to send formatted messages.
finalStats.foreachRDD(lambda rdd: rdd.foreachPartition(sendMetrics))
print("Starting the streaming context... Kill me with ^C")
ssc.start()
ssc.awaitTermination()
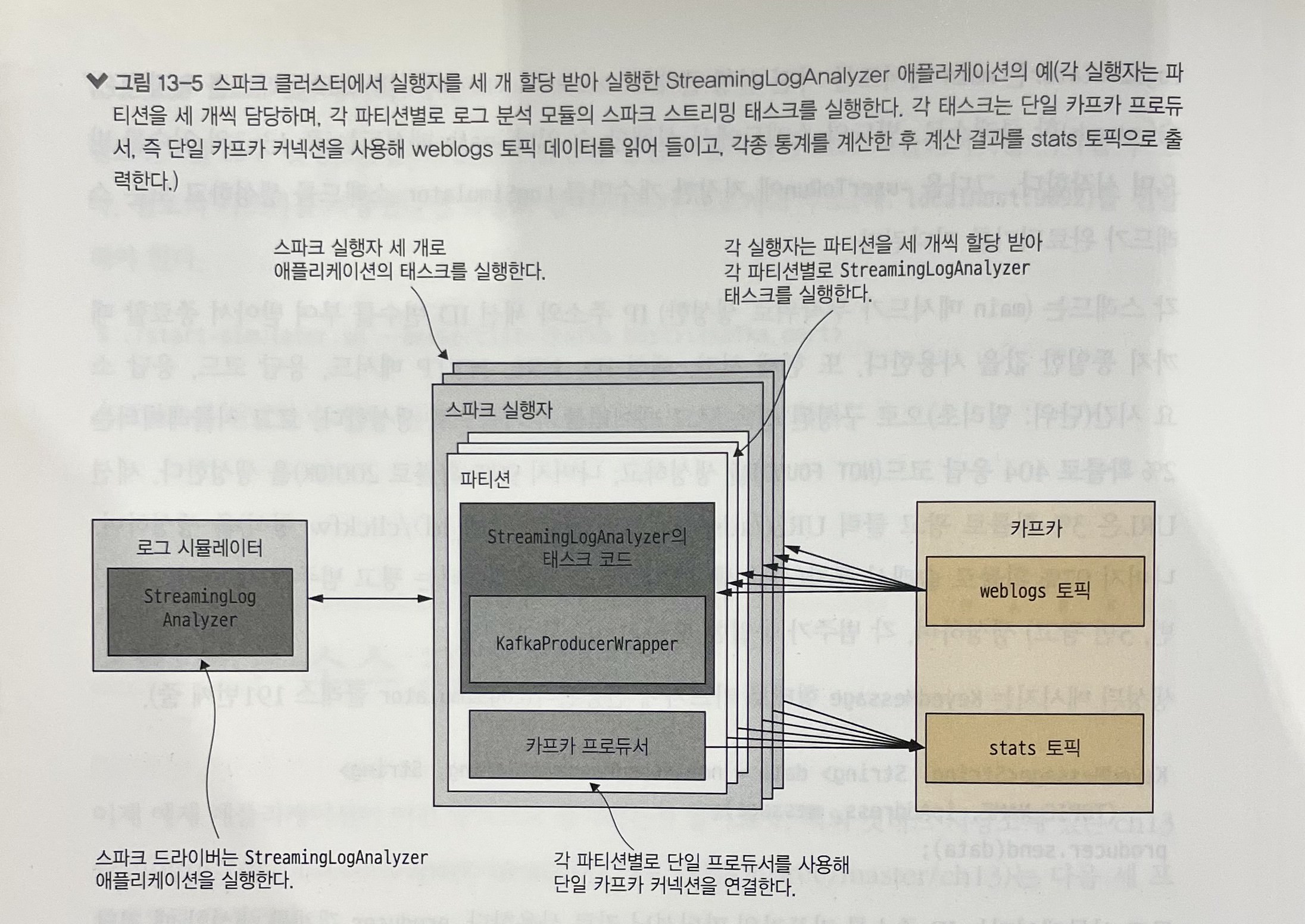
이 예제에서는 활성 세션 수가 1초 미니배치로 처리되기 때문에, 초당 타임스탬프를 키로 하는 결과를 합쳐 Kafka로 전송합니다.
Driver에서 초기화한 Kafka producer 객체는 worker로 전송할 수 없습니다. 대신 worker에서 실행되는 태스크 안에서 producer를 초기화합니다.
Scala의 KafkaProducerWrapper 동반 객체는 단일 인스턴스를 lazy instantiation 방식으로 만들고, 단일 Kafka producer 인스턴스를 초기화합니다.
foreachPartition을 사용하면 producer 객체를 JVM당 하나씩 초기화하고 메시지를 Kafka로 전송할 수 있습니다. 여러 파티션이 동일한 executor JVM을 공유하므로, producer 객체도 공유할 수 있는 구조로 볼 수 있습니다.
마무리
이번 글에서는 Spark의 런타임 컴포넌트, 리소스 스케줄링, 데이터 지역성, 메모리 스케줄링, 실시간 대시보드 예제를 정리했습니다.