스파크를 다루는 기술 2: 파티셔닝과 셔플링 이해하기
『스파크를 다루는 기술』 정리 두 번째 글입니다. 첫 번째 글에서 Spark의 기본 실행 흐름과 RDD를 살펴봤다면, 이번 글에서는 성능에 직접적인 영향을 주는 파티셔닝과 셔플링을 정리합니다.
Spark에서 파티션이 어떻게 나뉘고, 언제 데이터 이동이 발생하는지 이해하면 잡이 왜 느려지는지 훨씬 잘 보입니다.
데이터 파티셔닝
파티셔닝은 데이터를 여러 클러스터 노드로 나누는 과정입니다. Spark에서 파티셔닝은 성능과 리소스 점유량을 크게 좌우합니다.
RDD의 파티션은 RDD 데이터의 일부입니다. Spark는 파일을 파티션으로 분할해 클러스터 노드에 분산 저장하고, 이렇게 분산된 파티션의 집합이 하나의 RDD를 형성합니다.
파티션 개수는 클러스터에 작업을 분배하는 방식에 영향을 줍니다. RDD에 변환 연산을 실행할 때 생성되는 태스크 개수와도 직접 연결됩니다.
파티션이 너무 적으면 클러스터를 충분히 활용할 수 없습니다. 반대로 각 태스크가 처리할 데이터가 너무 많아져 executor의 메모리 리소스를 초과할 수도 있습니다.
일반적으로는 클러스터의 코어 개수보다 3~4배 많은 파티션을 사용하는 것이 좋다고 합니다. 다만 태스크가 지나치게 많아지면 태스크 관리 자체가 병목이 될 수 있습니다.
Partitioner
Partitioner는 RDD의 각 요소에 파티션 번호를 할당하면서 파티셔닝을 수행합니다.
HashPartitioner
HashPartitioner는 기본 파티셔너입니다. 각 요소의 Java 해시코드를 partitionIndex = hashCode % numOfPartitions 공식으로 계산해 파티션을 정합니다.
해시 기반이기 때문에 모든 파티션을 정확히 같은 크기로 나눈다고 보장할 수는 없습니다. 다만 파티션 수가 너무 적지 않다면 대체로 고르게 분산되는 편입니다.
RangePartitioner
RangePartitioner는 정렬된 RDD의 데이터를 거의 같은 범위 간격으로 분할합니다. 샘플링한 데이터를 기반으로 범위 경계를 결정합니다.
책에서는 실제로는 자주 사용하지 않는다고 설명합니다.
Pair RDD의 사용자 정의 Partitioner
키-값 쌍으로 구성된 Pair RDD를 처리할 때는 사용자 정의 Partitioner를 사용할 수 있습니다. 특정 기준에 따라 데이터를 원하는 파티션에 정확하게 배치해야 할 때 활용할 수 있습니다.
셔플링
셔플링은 파티션 간의 물리적인 데이터 이동을 의미합니다.
새로운 RDD의 파티션을 만들기 위해 여러 파티션의 데이터를 합쳐야 할 때 셔플링이 발생합니다.
val prods = transByCust.aggregateByKey(List[String]())(
(prods, tran) => prods ::: List(tran(3)),
(prods1, prods2) => prods1 ::: prods2
)
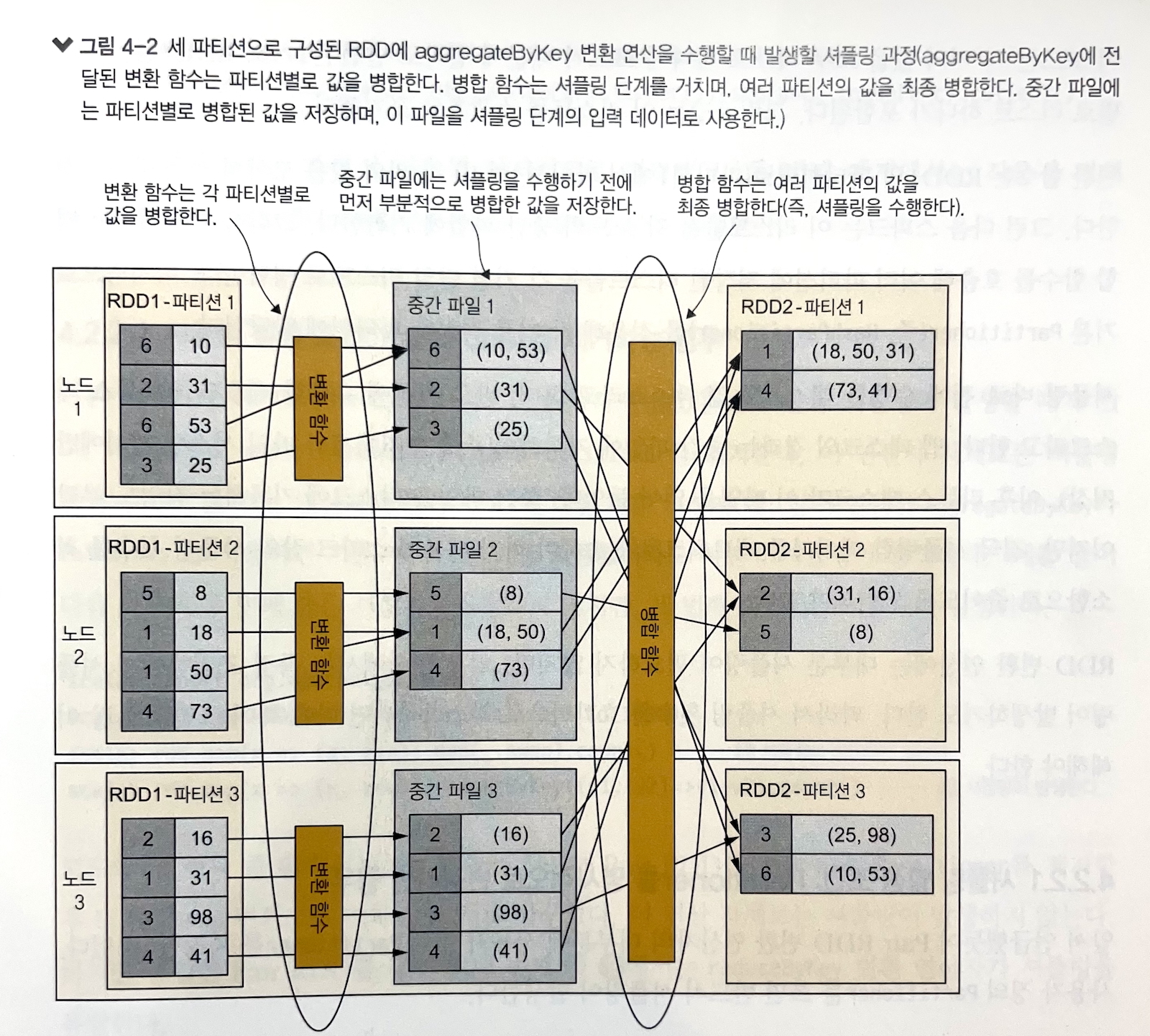
예를 들어 키를 기준으로 데이터를 그룹핑하려면, RDD의 모든 파티션을 살펴보고 키가 같은 요소를 찾아 물리적으로 묶어야 합니다. 이 과정에서 데이터가 파티션 사이를 이동합니다.
aggregateByKey에서는 두 종류의 함수가 사용됩니다.
- 변환 함수: 파티션별로 값을 병합해 값의 타입을 변경합니다.
- 병합 함수: 셔플링 단계를 거치며 여러 값을 하나로 최종 병합합니다.
셔플링 바로 전에 수행한 태스크를 맵 태스크라고 하고, 바로 다음에 수행한 태스크를 리듀스 태스크라고 합니다.
외부 셔플링 서비스
셔플링을 수행하면 executor는 다른 executor가 만든 중간 파일을 pull 방식으로 읽어야 합니다. 그런데 중간에 장애가 발생하면 해당 executor가 처리한 데이터를 가져올 수 없어 작업이 중단될 수 있습니다.
외부 셔플링 서비스는 executor가 중간 셔플 파일을 읽을 수 있는 단일 지점을 제공해 데이터 교환 과정을 최적화합니다.
셔플링 관련 매개변수
대표적인 설정은 다음과 같습니다.
spark.shuffle.manager: 셔플링 알고리즘을 설정합니다.hash,sort를 사용할 수 있으며 기본값은sort입니다.spark.shuffle.consolidateFiles: 셔플링 중 생성된 중간 파일을 통합할지 설정합니다. 기본값은false입니다.spark.shuffle.spill: 메모리 리소스를 초과할 경우 데이터를 디스크로 내보낼지 설정합니다. 기본값은true입니다.
불필요한 셔플링 줄이기
Spark 작업의 성능을 개선하려면 불필요한 셔플링을 줄이는 것이 중요합니다. 셔플링은 네트워크와 디스크 I/O를 동반하기 때문에 비용이 큽니다.
Partitioner를 명시적으로 변경하는 경우
사용자 정의 Partitioner를 사용하거나, 이전 HashPartitioner와 파티션 개수가 다른 HashPartitioner를 사용하면 셔플링이 발생합니다.
가능하다면 기본 Partitioner를 유지하는 편이 좋습니다.
Partitioner를 제거하는 경우
map, flatMap은 Partitioner를 제거합니다. 이후 join, groupByKey 같은 연산자를 사용하면 셔플링이 발생할 수 있습니다.
키를 변경할 필요가 없다면 mapValues, flatMapValues를 사용하는 편이 좋습니다. 파티션 안에서만 데이터가 매핑되도록 mapPartitions, mapPartitionsWithIndex, glom 등을 사용하고 preservePartitioning = true로 설정하는 방법도 있습니다.
RDD 파티션 변경
작업 부하를 분산시키기 위해 파티셔닝을 명시적으로 변경해야 할 때가 있습니다.
partitionBy
partitionBy는 Pair RDD에서만 사용할 수 있습니다. 파티셔닝에 사용할 Partitioner 객체를 인자로 전달해 새로운 RDD를 생성합니다.
coalesce
coalesce는 파티션 개수를 변경할 때 사용합니다.
파티션 개수를 줄일 때는 새로운 파티션 개수와 동일한 수의 부모 RDD 파티션을 선정하고, 나머지 파티션의 요소를 분할해 병합합니다.
shuffle = false로 설정하면 coalesce 이전의 변환 연산자도 현재 파티션 개수를 사용합니다. 반대로 shuffle = true로 설정하면 coalesce 이전의 변환 연산자는 원래 파티션 개수를 사용하고, 그 이후만 변경된 파티션 개수를 사용합니다.
repartition
repartition은 shuffle을 true로 설정해 coalesce를 호출한 결과와 같습니다.
repartitionAndSortWithinPartition
repartitionAndSortWithinPartition은 새로운 Partitioner를 받아 각 파티션 안에서 요소를 정렬합니다. 셔플링 단계에서 정렬 작업을 함께 수행하므로, repartition을 호출한 뒤 따로 정렬하는 것보다 성능이 좋습니다.
RDD 의존 관계
Spark의 실행 모델은 DAG입니다. DAG는 RDD를 정점으로, RDD 사이의 의존 관계를 간선으로 정의한 그래프입니다.
변환 연산자를 호출할 때마다 새로운 간선이 생성됩니다. 새 RDD는 이전 RDD에 의존하고, 이 그래프를 RDD lineage라고 합니다.
RDD 의존 관계는 크게 좁은 의존 관계와 넓은 의존 관계로 나눌 수 있습니다.
좁은 의존 관계
좁은 의존 관계는 데이터를 다른 파티션으로 전송할 필요가 없는 변환 연산에서 생깁니다.
- 1:1 의존 관계:
union을 제외한 대부분의 연산이 여기에 해당합니다. - 범위형 의존 관계: 여러 부모 RDD에 대한 의존 관계를 하나로 결합합니다.
union이 여기에 해당합니다.
넓은 의존 관계
넓은 의존 관계는 셔플링을 수행할 때 형성됩니다. 예를 들어 join을 수행할 때는 반드시 넓은 의존 관계가 생깁니다.
스테이지
Spark는 셔플링이 발생하는 지점을 기준으로 하나의 Spark 잡을 여러 스테이지로 나눕니다.
스테이지 결과는 중간 파일 형태로 executor 머신의 디스크에 저장됩니다. Spark는 각 스테이지와 파티션별로 태스크를 생성해 executor에 전달합니다.
스테이지가 셔플링으로 끝나는 경우 이를 셔플-맵 태스크라고 합니다. 마지막 스테이지에 생성된 태스크는 결과 태스크라고 합니다.
체크포인트
RDD lineage가 너무 길어지면 장애 발생 시 복구 비용이 커집니다. 이때 체크포인트를 사용해 RDD 데이터 전체를 중간에 저장할 수 있습니다.
장애가 발생하면 처음부터 모든 연산을 다시 수행하지 않고, 체크포인트로 저장된 시점부터 복구할 수 있습니다.
마무리
이번 글에서는 Spark의 파티셔닝, 셔플링, RDD 의존 관계를 정리했습니다.
다음 글에서는 Spark 애플리케이션이 실제로 어떤 컴포넌트로 실행되는지, 그리고 클러스터 리소스와 태스크가 어떻게 스케줄링되는지 살펴보겠습니다.