Spark in Action 2: Understanding Partitioning and Shuffling
This is the second post in my notes on Spark in Action by Petar Zečević and Marko Bonaći. In the first post, I looked at Spark’s basic execution flow and RDDs. In this post, I will summarize partitioning and shuffling, which directly affect performance.
Understanding how partitions are divided in Spark and when data movement occurs makes it much easier to see why a job becomes slow.
Data Partitioning
Partitioning is the process of splitting data across multiple cluster nodes. In Spark, partitioning has a major impact on performance and resource usage.
An RDD partition is a subset of RDD data. Spark splits files into partitions and stores them across cluster nodes, and the set of these distributed partitions forms a single RDD.
The number of partitions affects how work is distributed across the cluster. It is also directly connected to the number of tasks created when transformation operations are executed on an RDD.
If there are too few partitions, the cluster cannot be fully utilized. Conversely, each task may have to process too much data and exceed the executor’s memory resources.
In general, it is said to be good to use three to four times as many partitions as the number of cores in the cluster. However, if there are too many tasks, task management itself can become a bottleneck.
Partitioner
A Partitioner performs partitioning by assigning a partition number to each element of an RDD.
HashPartitioner
HashPartitioner is the default partitioner. It calculates the partition using each element’s Java hash code with the formula partitionIndex = hashCode % numOfPartitions.
Because it is hash-based, it cannot guarantee that all partitions will be exactly the same size. However, as long as the number of partitions is not too small, the data is generally distributed fairly evenly.
RangePartitioner
RangePartitioner splits data in a sorted RDD into roughly equal range intervals. It determines range boundaries based on sampled data.
The book explains that it is not often used in practice.
Custom Partitioner for Pair RDDs
When processing Pair RDDs composed of key-value pairs, a custom Partitioner can be used. It is useful when data must be placed into specific partitions according to a particular criterion.
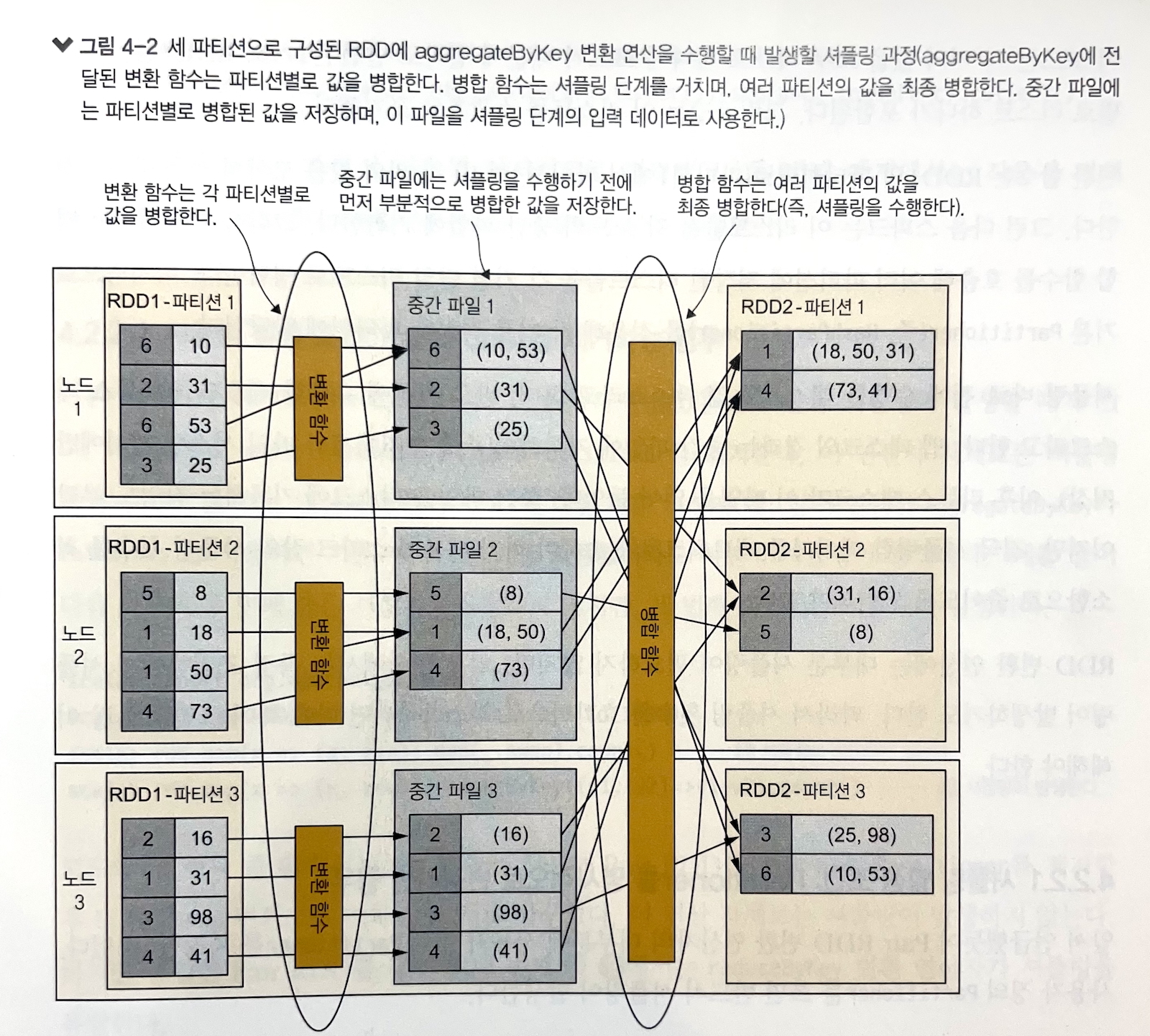
Shuffling
Shuffling refers to physical data movement between partitions.
Shuffling occurs when data from multiple partitions must be combined to create partitions for a new RDD.
val prods = transByCust.aggregateByKey(List[String]())(
(prods, tran) => prods ::: List(tran(3)),
(prods1, prods2) => prods1 ::: prods2
)
For example, to group data by key, Spark must look through all partitions of the RDD and physically gather elements with the same key. During this process, data moves between partitions.
Two types of functions are used in aggregateByKey.
- Transformation function: merges values within each partition and changes the value type.
- Merge function: performs final merging of multiple values through the shuffling stage.
The task performed immediately before shuffling is called a map task, and the task performed immediately after is called a reduce task.
External Shuffle Service
When shuffling is performed, executors must read intermediate files produced by other executors using a pull method. If a failure occurs in the middle, the data processed by that executor may become unavailable and the job may stop.
An external shuffle service provides a single point where executors can read intermediate shuffle files, optimizing the data exchange process.
Shuffle-Related Parameters
Representative settings include the following.
spark.shuffle.manager: configures the shuffling algorithm.hashandsortcan be used, and the default issort.spark.shuffle.consolidateFiles: configures whether intermediate files generated during shuffling should be consolidated. The default isfalse.spark.shuffle.spill: configures whether data should be spilled to disk when memory resources are exceeded. The default istrue.
Reducing Unnecessary Shuffling
To improve Spark job performance, reducing unnecessary shuffling is important. Shuffling is expensive because it involves network and disk I/O.
When Explicitly Changing the Partitioner
Shuffling occurs when using a custom Partitioner or a HashPartitioner with a different number of partitions from the previous HashPartitioner.
If possible, it is better to keep the default Partitioner.
When Removing the Partitioner
map and flatMap remove the Partitioner. If operators such as join or groupByKey are used afterward, shuffling may occur.
If there is no need to change the key, it is better to use mapValues or flatMapValues. Another option is to use mapPartitions, mapPartitionsWithIndex, glom, and similar methods so that data is mapped only within partitions, while setting preservePartitioning = true.
Changing RDD Partitions
There are cases where partitioning must be explicitly changed to distribute workload.
partitionBy
partitionBy can be used only on Pair RDDs. It creates a new RDD by receiving a Partitioner object to use for partitioning.
coalesce
coalesce is used to change the number of partitions.
When reducing the number of partitions, it selects the same number of parent RDD partitions as the new number of partitions, then splits and merges elements from the remaining partitions.
If shuffle = false is set, transformation operators before coalesce also use the current number of partitions. Conversely, if shuffle = true is set, transformation operators before coalesce use the original number of partitions, and only the operations afterward use the changed number of partitions.
repartition
repartition is equivalent to calling coalesce with shuffle set to true.
repartitionAndSortWithinPartition
repartitionAndSortWithinPartition receives a new Partitioner and sorts elements within each partition. Since sorting is performed together during the shuffling stage, it performs better than calling repartition and then sorting separately.
RDD Dependencies
Spark’s execution model is a DAG. A DAG is a graph that defines RDDs as vertices and dependencies between RDDs as edges.
Whenever a transformation operator is called, a new edge is created. The new RDD depends on the previous RDD, and this graph is called RDD lineage.
RDD dependencies can be broadly divided into narrow dependencies and wide dependencies.
Narrow Dependencies
Narrow dependencies occur in transformation operations that do not require data to be transferred to other partitions.
- One-to-one dependency: most operations except
unionfall into this category. - Range dependency: combines dependencies on multiple parent RDDs into one.
unionfalls into this category.
Wide Dependencies
Wide dependencies are formed when shuffling is performed. For example, a join always creates a wide dependency.
Stages
Spark divides a single Spark job into multiple stages based on the points where shuffling occurs.
Stage results are stored as intermediate files on the disks of executor machines. Spark creates tasks for each stage and partition, then passes them to executors.
When a stage ends with shuffling, it is called a shuffle-map task. Tasks created in the final stage are called result tasks.
Checkpoints
If RDD lineage becomes too long, recovery cost increases when a failure occurs. In this case, checkpoints can be used to store the entire RDD data at an intermediate point.
If a failure occurs, Spark can recover from the checkpoint instead of re-running all operations from the beginning.
Closing
In this post, I summarized Spark partitioning, shuffling, and RDD dependencies.
In the next post, I will look at which components a Spark application actually runs as, and how cluster resources and tasks are scheduled.